Machine Learning Theory
Reference
Linear Regression
§1 prior knowledge
Maximum Likelihood Estimation
(Maximum Likelihood Estimation,MLE)
Matrix derivatives
The exponential family
Multinomial Distribution
多项分布的概率分布函数为:
$$ \mathrm{P}\left(\mathrm{X}{1}=\mathrm{k}{1},\mathrm{X}{2}=\mathrm{k}{2},\cdots,\mathrm{X}{\mathrm{n}}=\mathrm{k}{\mathrm{n}}\right)=\dfrac{\mathrm{n}!}{\mathrm{k}{1}!\mathrm{k}{2}!\cdots\mathrm{k}{\mathrm{n}}!}\prod{i=1}^{\mathrm{n}}\mathrm{p}{i}^{\mathrm{k}{i}}\quad,\sum_{i=1}^{\mathrm{n}}\mathrm{k}_{i}=\mathrm{n} $$§2 Linear Regression
Object function:
$$ h(x) = \theta^{\mathrm{T}}x; $$Cost function:
$$ J(\theta) = \frac{1}{2} \sum\limits_{i=1}^{n} (h_\theta(x_i) - y_i)^2 $$方法一,通过 gradient descent 方法调整参数 $\theta$。
首先计算梯度方向,
$$ \begin{aligned} \frac{\partial}{\partial\theta_j}J(\theta) &=\frac{\partial}{\partial\theta_j}\frac{1}{2}\left(h_\theta(x)-y\right)^2\\ &=2\cdot\frac{1}{2}\left(h_\theta(x)-y\right)\cdot\frac{\partial}{\partial\theta_j}\left(h_\theta(x)-y\right)\\ &=\left(h_\theta(x)-y\right)\cdot\frac{\partial}{\partial\theta_j}\left(\sum_{i=0}^{d}\theta_ix_i-y\right)\\ &=\left(h_\theta(x)-y\right)x_j \end{aligned} $$根据下式迭代调整 $\theta$ 参数。
$$ \theta_j:=\theta_j+\alpha\left(y^{(i)}-h_\theta(x^{(i)})\right)x_j^{(i)}. $$方法二,通过 closed-form solution 直接求得最优参数,即最小二乘法。
首先计算损失函数 $J(\theta) = \frac{1}{2} \sum\limits_{i=1}^{n} (h_\theta(x_i) - y_i)^2$ 的梯度,
$$ \begin{aligned} \nabla_\theta J(\theta) &=\nabla_\theta\frac{1}{2}(X\theta-\vec{y})^T(X\theta-\vec{y})\\ &=\frac{1}{2}\nabla_\theta((X\theta)^T X\theta-(X\theta)^T\vec{y}-\vec{y}^T(X\theta)+\vec{y}^T\vec{y})\\ &=\frac{1}{2}\nabla_\theta(\theta^T(X^T X)\theta-\vec{y}^T(X\theta)-\vec{y}^T(X\theta))\\ &=\frac{1}{2}\nabla_\theta\left(\theta^T(X^T X)\theta-2(X^T\vec{y})^T\theta\right)\\ &=\frac{1}{2}\left(2X^T X\theta-2X^T\vec{y}\right)\\ &=X^T X\theta-X^T\vec{y}\\ \end{aligned} $$令 $\nabla_\theta J(\theta) = 0$,得
$$ \theta = (X^TX)^{-1}X^T \overrightarrow{y} $$💡 概率解释,为什么选择 $J(\theta) = \frac{1}{2} \sum\limits_{i=1}^{n} (h_\theta(x_i) - y_i)^2$ 作为 cost function?
根据线性模型 $h(x) = \theta^{\mathrm{T}}x + \varepsilon$,其中 $\varepsilon$ 是随机噪声,假设 $\varepsilon$ 满足标准正态分布,即 $\varepsilon \sim\mathcal{N}(\mu,\sigma^2), \mu = 0, \sigma = 1$,则有
$$ p(\varepsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{{\varepsilon^{(i)}}^2}{2\sigma^2}\right) \\ $$若将标签 $y^{(i)}$ 与 $\theta^{\mathrm{T}}x$ 认为是随机变量,$p(y^{(i)}|x^{(i)};\theta)$ 描述了当特征 $x$ 确定时实际标签 $y^{(i)}$ 的概率分布函数,$\theta^{\mathrm{T}}x$ 表明了特征 $x$ 下的预测值。
因为随机噪声 $\varepsilon$ 满足标准正态分布,其平均值 $\mu = 0$,即表明实际输出 $y^{(i)}$ 是以 $\theta^{\mathrm{T}}x$ 为平均值的正态分布,则有
$$ p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\right) $$从似然的角度考虑 $p(y^{(i)}|x^{(i)};\theta)$,基于已有的数据知识 ($\overrightarrow{y}, X$) 获得 $\mathrm{argmax}_{\theta} p(\theta;\overrightarrow{y}, X)$。根据极大似然法,最大化函数
$$ \begin{aligned}L(\theta)&=\prod_{i=1}^np(y^{(i)}\mid x^{(i)};\theta)\\&=\prod_{i=1}^n\frac1{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\right).\end{aligned} $$等价于最大化函数
$$ \begin{aligned} \ell(\theta)& =\log L(\theta) \\ &=\log\prod_{i=1}^n\frac1{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\right)\\ &=\sum_{i=1}^n\log\frac1{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}\right) \\ &=n\log\frac1{\sqrt{2\pi}\sigma}-\frac1{\sigma^2}\cdot\frac12\sum_{i=1}^n(y^{(i)}-\theta^Tx^{(i)})^2.\end{aligned} $$等价于最小化
$$ \frac12\sum_{i=1}^n(y^{(i)}-\theta^Tx^{(i)})^2. $$即线性回归模型使用的代价函数。
§3 Logistic Regression
根据极大似然法,逻辑回归中由 $ x $ 给出的 $ y $ 满足二项分布 (Bernoulli distribution),概率分布为:
$$ \begin{aligned} p(y|x;\theta)&=(h_\theta(x))^y(1-h_\theta(x))^{1-y} \\ h_{\theta}(x)&=g(\theta^T x) \end{aligned} $$这里 $g(\cdot)$ 是联系函数(link function),$g(\cdot)=\frac{1}{1+e^{-x}}$,称之为 logistic function (或 sigmoid 函数)。
$g(\cdot)=\frac{1}{1+e^{-x}}$ 该函数的导数恰为 $g'(x)=g(x)(1-g(x))$
$$\begin{aligned}g^{\prime}(z)& =\frac d{dz}\frac1{1+e^{-z}}\\&=\frac1{(1+e^{-z})^2}(e^{-z}) \\&=-\frac1{(1+e^{-z})}\cdot(1-\frac1{(1+e^{-z})}) \\&=g(z)(1-g(z)).\end{aligned}$$
使 $L(\theta)=p(y|x;\theta)$ 最大,
$$ \begin{aligned} L(\theta) &=p(\vec{y}\mid X;\theta)\\ &=\prod\limits_{i=1}^np(y^{(i)}\mid x^{(i)};\theta)\\ &=\prod\limits_{i=1}^n\left(h_\theta(x^{(i)})\right)^{y^{(i)}}\left(1-h_\theta(x^{(i)})\right)^{1-y^{(i)}} \end{aligned} $$为求解方便,对 $L(\theta)$ 取对数,
$$ \begin{array}{rcl} \ell(\theta) &=&\log L(\theta)\\ &=&\sum_{i=1}^n y^{(i)}\log h(x^{(i)})+(1-y^{(i)})\log(1-h(x^{(i)})) \end{array} $$不考虑 $\sum_{i=1}^n$ 时,对 $\ell(\theta)$ 求导,
$$ \begin{aligned} \frac{\partial}{\partial\theta_j}\ell(\theta) &=\left(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)}\right)\frac{\partial}{\partial\theta_j}g(\theta^Tx)\\ &=\left(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)}\right)g(\theta^Tx)(1-g(\theta^Tx))\frac{\partial}{\partial\theta_j}\theta^Tx\\ &=\left(y(1-g(\theta^Tx))-(1-y)g(\theta^Tx)\right)x_j\\ &=(y-g(\theta^Tx))\:x_j\\ &=(y-h_\theta(x))x_j \end{aligned} $$根据 gradient descent rule 更新参数 $\theta$。
$$ \begin{aligned} \theta_j&:=\theta_j+\alpha\left(y^{(i)}-h_\theta(x^{(i)})\right)x_j^{(i)}\\ &=\theta_j+\alpha\left(y^{(i)}-\frac{1}{1+\exp^{-(\omega x+b)}}\right)x_j^{(i)}\\ \end{aligned} $$这里形式上与线性模型相同,其中不同在于 $h(\theta)$,线性模型中为 $h(\theta)=\omega x+b$,此处为 $h(\theta)=g(\omega x+b)=\frac{1}{1+\exp^{-(\omega x+b)}}$。
拓展学习:
- 考虑 $g(z)=\left\{\begin{array}{ll}1&\mathrm{if~}z\geq0\\0&\mathrm{if~}z<0\end{array}\right.$ 时,该模型与线性回归和逻辑回归模型的区别。
- 牛顿法是一种逼近极值的方法,参考 牛顿法 Wiki。
§4 Generalized Linear Models
(Generalized Linear Models, GLMs)
Linear Regression
Logistic Regression
Softmax Regression
Softmax Regression 用于多分类场景,这里我们假设多分类场景中 $y$ 满足指数族分布,即 $y|x,\theta \sim ExponentialFmaily(\theta$),且这里的指数族分布为多项分布(Multinomial Distribution)。
$$ \begin{aligned} p(y|x;\theta) &=\phi_1^{1\{y=1\}}\phi_2^{1\{y=2\}}\phi_3^{1\{y=3\}}\cdots\phi_k^{1\{y=k\}}\\ &=\phi_1^{1\{y=1\}}\phi_2^{1\{y=2\}}\phi_3^{1\{y=3\}}\cdots\phi_k^{1-\sum_{i=1}^{k-1}1\{y=i\}}\\ &=\phi_1^{(T(y))_1}\phi_2^{(T(y))_2}\phi_3^{(T(y))3}\cdots\phi_k^{1-\sum{i=1}^{k-1}(T(y))_k}\\ &=\exp((T(y))_1log(\phi_1)+(T(y))_2log(\phi_2)+(T(y))_3log(\phi_3)+\\ &\quad\cdots+(1-\sum_{i=1}^{k-1}(T(y))_k)log(\phi_k))\\ &=\exp((T(y))_1log(\frac{\phi_1}{\phi_k})+(T(y))_2log(\frac{\phi_2}{\phi_k})+(T(y))_3log(\frac{\phi_3}{\phi_k})+\\ &\quad\cdots+(T(y))_klog(\phi_k))\\ &=b(y)\exp(\eta^TT\left(y\right)-a\left(\eta\right))\\ \end{aligned} $$根据指数族分布形式可知,
$$ \begin{array}{rcl} \eta &=& \left[\begin{array}{} \log(\frac{\phi_1}{\phi_k})\\ \log(\frac{\phi_2}{\phi_k})\\ \vdots\\ \log(\frac{\phi_k-1}{\phi_k}) \end{array}\right]\\ a(\eta)&=&-log(\phi_k)\\ b(y)&=&1 \end{array} $$这里假设 $T(y)=y;h(\theta)=E[y|x]$,则有,
$$ \begin{array}{rcl}h_{\theta}(x) &=&\text{E}[T(y)|x;\theta]\\ &=&E\left[\begin{array}{c|c} \begin{matrix} 1\{y=2\}\\ 1\{y=2\}\\ \vdots\\ 1\{y=k-1\} \end{matrix}& x;\theta \end{array}\right]\\ &=&\left[ \begin{matrix} \phi_1\\ \phi_2\\ \vdots\\ \phi_{k-1} \end{matrix} \right]\\ &=&\left[ \begin{matrix} \frac{\exp(\theta_1^Tx)}{\sum_{j=1}^{k}\exp(\theta_j^Tx)}\\ \frac{\exp(\theta_2^Tx)}{\sum_{j=1}^{k}\exp(\theta_j^Tx)}\\ \vdots\\ \frac{\exp(\theta_{k-1}^Tx)}{\sum_{j=1}^{k}\exp(\theta_j^Tx)}\\ \end{matrix} \right]\end{array} $$根据多项分布的概率分布函数,将 $h(\theta)$ 代入概率分布函数,根据极大似然求对应的 $\theta$。
$$ \begin{array}{rcl}\ell(\theta) &=&\sum\limits_{i=1}^n\log p(y^{(i)}|x^{(i)};\theta)\\ &=&\sum\limits_{i=1}^n\log\prod\limits_{l=1}^k\left(\dfrac{e^{\theta_l^Tx^{(i)}}}{\sum\limits_{j=1}^ke^{\theta_j^Tx^{(i)}}}\right)^{1\{y^{(i)}=l\}}\end{array} $$可以通过 gradient ascent 或 Newton’s method 进行求解。
Generative learning algorithms
What are Generative learning algorithms?
生成式模型和判别式模型的区别在于,判别式模型直接学习 $p(y|x)$ 条件概率模型,而生成式模型先学习 $p(y)$ 先验概率,然后根据贝叶斯定理获得 $p(y|x)$ 的条件概率模型。
$$ \begin{aligned} p(y|x) &= \frac{p(x|y)p(y)}{p(x)}\\ argmax p(y|x) &= argmax \frac{p(x|y)p(y)}{p(x)} \\ &= argmax {p(x|y)p(y)} \end{aligned} $$§1 Gaussian discriminant analysis
假设
$$ \begin{aligned} y&\sim\mathrm{Bernoulli}(\phi)\\ x|y=0&\sim\mathcal{N}(\mu_0,\Sigma)\\ x|y=1&\sim\mathcal{N}(\mu_1,\Sigma)\\ \end{aligned} $$§2 Naive bayes
Support vector machines
有数据集 $S = \{x_i, y_i\}, x_i \in R^n, y_i \in \{-1, 1\}$,支持向量机的超平面将 $S$ 按照 $y$ 正确的划分为两类。超平面为
$$ w^{T}x + b = 0 $$预测函数为
$$ h_{w, b}(x) = sign(w^{T}x + b) $$Margin
某一样本点函数间隔 (function margin) 定义为
$$ \hat{\gamma}^{(i)}=y^{(i)}(w^Tx^{(i)}+b) $$在 $S$ 上,则有
$$ \hat{\gamma} = \min_{S} \hat{\gamma}^{(i)} $$$|w^Tx^{(i)}+b|$ 可相对地表示样本点到超平面的距离,而 $y^{(i)}$ 则能表示分类是否正确,因此 $\hat{\gamma}^{(i)}$ 能够表示点的函数间隔。
等比例的放大 $w$ 和 $b$ 不会改变超平面,而 $\hat{\gamma}$ 却会成比例的放大,$\hat{\gamma}$ 不能衡量实际的超平面到最近样本点的间隔,因此有在 $S$ 上的几何间隔 (geometric margin)
$$ \gamma=\min_{S} y^{(i)}\frac{w^Tx^{(i)}+b}{||w||} $$因此函数间隔和几何间隔之间存在关系
$$ \gamma = \frac{\hat{\gamma}}{||w||} $$The optimal margin classifier
当间隔 (margin) 越大时,我们对 SVM 的分类结果更有信心,有
$$ \begin{array}{rl}\max_{\gamma,w,b}&\gamma\\ \mathrm{s.t.}&y^{(i)}(w^Tx^{(i)}+b)\geq\gamma,\quad i=1,\ldots,n\\ &||w||=1. \end{array} $$其中 $\gamma$ 可以替换为 $\frac{\hat{\gamma}}{||w||}$,则有等价
$$ \begin{array}{rl}\min_{w,b}&\frac12||w||^2\\\mathrm{s.t.}&y^{(i)}(w^Tx^{(i)}+b)\geq1,&i=1,\ldots,n\end{array} $$Lagrange duality
Neural Network
What is Neural Network?
神经网络是由线性函数和激活函数 (activation function) 组合构成的多层网状函数结构,可表示为
$$ a^{[k]}=\text{ReLU}(W^{[k]}a^{[k-1]}+b^{[k]}),\forall k=1,\ldots,r-1 $$其中 ReLu(Recitified linear function) 是一种激活函数,$a^{[k]}$ 是第 $k$ 层的神经元 ( $a^{[0]}$ 为输入),$W^{[k]}$ 是第 $k$ 层的参数。
Activation Function
ReLU 线性整流函数的定义如下
$$ ReLU(x) = \max\{x, 0\} $$Backpropagation
Reference
《动手学深度学习》 — 动手学深度学习 2.0.0 documentation
Generalization
Bias-Variance of Model
有 $S = \{x^{(i)}, y^{(i)}\}_i^n, y^{(i)} = h^{\star}(x^{(i)}) + \xi^{(i)}, \xi \sim N(\mu,\sigma^2)$,从 $S$ 中学习到模型 $\hat{h}_{S}(x)$,则
$$ \begin{aligned} \mathrm{MSE}(x)& =\sigma^2+\mathbb{E}[(h^\star(x)-h_S(x))^2] \\ &=\sigma^2+(h^\star(x)-h_{\mathrm{avg}}(x))^2+\mathbb{E}[(h_{\mathrm{avg}}-h_S(x))^2] \\ &=\underbrace{\sigma^2}_\text{unavoidable}+\underbrace{(h^\star(x)-h_{\mathrm{avg}}(x))^2}_{\triangleq \text{bias}^2\ }+\underbrace{\mathrm{var}(h_S(x))}_\text{ variance} \end{aligned} $$Double descent phenomenon
Deep Double Descent: Where Bigger Models and More Data Hurt - from arxiv
从模型的角度出发,双重下降现象是指测试误差随着模型复杂度的提升出现二次降低的现象。
从样本的角度出发,双重下降现象是指,测试误差随着样本数量增加出现二次降低的现象。
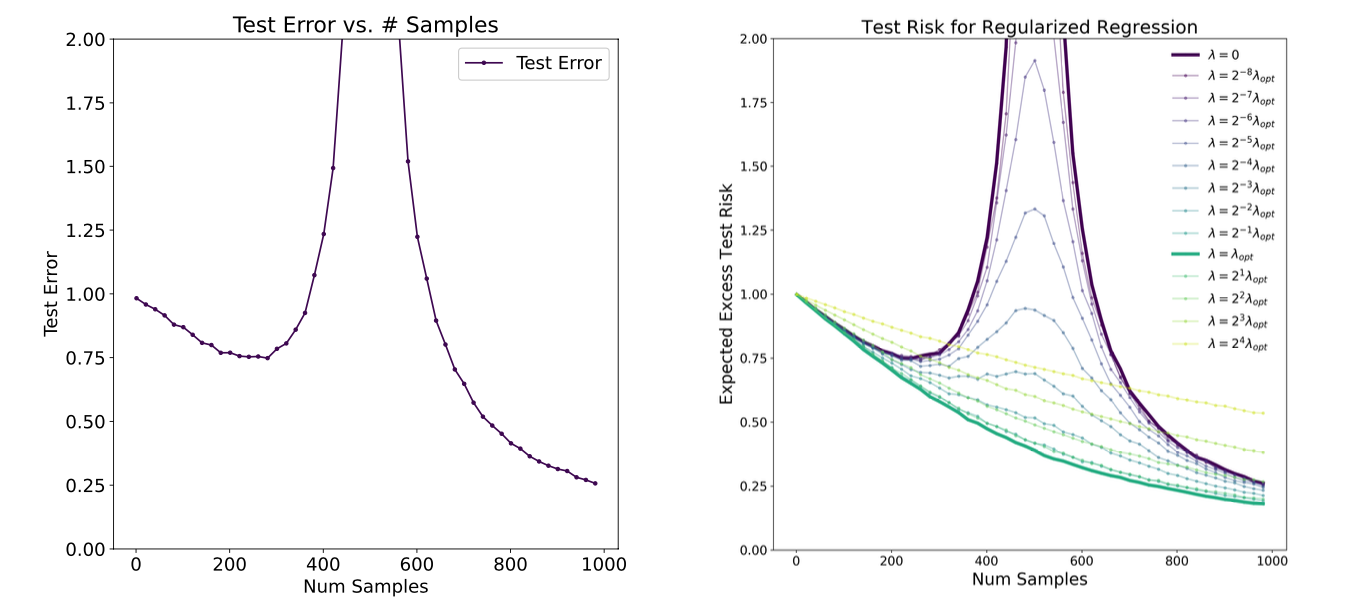
综合上述两种角度,当模型参数的数量 $d$ 与样本数量 $n$ 接近时,即 $n \approx d$,测试误差会达到最大值。
Sample complexity bound
Regularization
Regularization
Implicit regularization effect
Bayes statistics
Evaluation
Model Select
Cross Validation
- hold-out cross validation
- k-fold cross validation
- levave-one-out cross validation
Performance
有查准率 P(precision) 与查全率 R(recall),F1 指标是 P 和 R 的调和平均 (harmonic mean):,
$$ \frac1{F1}=\frac12\cdot\left(\frac1P+\frac1R\right) $$有 真正例率TPR(True Positive Rate), 假正例率 FPR(False Positive Rate),
$$ \begin{aligned} TPR = \frac{TP}{TP + FN}\\ FPR = \frac{FP}{FP+TN}\\ \end{aligned} $$由 FPR 为横坐标,TPR 为纵坐标构成受测者工作特征 ROC(Reciver Operating Characteristic),曲线下面积即 AUC(Area Under Curve)。
💡 如何理解 AUC 的实际意义?
一般地,在二分类问题中,设正例的数量为 $n^+$,而反例的数量为 $n^-$。
模型 $h(x^{(i)})$ = $P(y^{(i)}=1|x^{(i)})$,有序集合 $S = \{x|h(x^{(i)}) < h(x^{(i+1)})\}$。假设 $h(x^{(i)})$ 为正反例分界阈值,对每一个 $i$ 则有
$$ \begin{array}{rcl} FPR^{(0)} &=& 0\\ FPR^{(i)} &=& \left\{\begin{array}{clr} FPR^{(i-1)},&,& y_i=1\\ FPR^{(i-1)}+\frac{1}{n^-} &,& y_i\neq1\\ \end{array}\right.\\ TPR^{(0)} &=& 0\\ TPR^{(i)} &=& \left\{\begin{array}{clr} TPR^{(i-1)}+\frac{1}{n^+} &,& y_i=1\\ TPR^{(i-1)},&,& y_i\neq1\\ \end{array}\right.\\ \end{array} $$则 ROC 曲线由点集 $O = \{FPR^{(i)}, TPR^{(i)}\}$ 依次连线构成。简而言之,模型 $h(x)$ 输出的有序集合 $S$ 产生 FPR 和 TPR,ROC 正是 FPR-TRP 曲线。
样本点为正例时,ROC 曲线沿 y 轴增长,反之沿 x 轴增长。当有序集合 $S$ 排序后的前 $n^+$ 个样本点中正例比例越大时,ROC 曲线优先沿 y 轴增长,后沿 x 轴增长,则此时 AUC 越大。
因此 AUC 实际反映了模型预测的前 n 个正例是否正确,即预测正例排序是否符合实际数据情况。
K-means alogrithm
$x$ 为样本点,$\mu$ 为聚簇中心,重复下述步骤直至收敛:
$$ \begin{array}{} \text{For every i, set}&\\ &c^{(i)}:=\arg\min_j||x^{(i)}-\mu_j||^2 \\ \text{For each j, set}&\\ &\mu_j:=\frac{\sum_{i=1}^n1\{c^{(i)}=j\}x^{(i)}}{\sum_{i=1}^n1\{c^{(i)}=j\}} \end{array} $$EM algorithm
期望极大算法 EM (Expectation-Maximization)
$x$ 为输出值,$z$ 为隐变量 (latent variable),$p(z;\phi)$ 描述隐变量的概率分布,$p(x|z;\mu,\Sigma)$ 描述 $z$ 条件下的 $x$ 概率分布 ,$p(x,z;\phi,\mu,\Sigma)$ 描述输出值的概率分布。
E-step:
$$ \begin{array}{} \text{(E-step) For each }i,j,\mathrm{~set}&\\ &w_j^{(i)}:=p(z^{(i)}=j|x^{(i)};\phi,\mu,\Sigma) \end{array} $$M-step:
$$ \begin{aligned}&\phi_j\quad:=\quad\frac1n\sum_{i=1}^nw_j^{(i)},\\&\mu_j\quad:=\quad\frac{\sum_{i=1}^nw_j^{(i)}x^{(i)}}{\sum_{i=1}^nw_j^{(i)}},\\&\Sigma_j\quad:=\quad\frac{\sum_{i=1}^nw_j^{(i)}(x^{(i)}-\mu_j)(x^{(i)}-\mu_j)^T}{\sum_{i=1}^nw_j^{(i)}}\end{aligned} $$