Large Language Model
PEFT
- Adapter Layers
nips_2017_learning_multiple_visual_domains_with_residual_adapters.pdf
pmlr_2019_parameter_efficient_transfer_learning_for_nlp.pdf
- prefix tunning
prefix_tuning_optimizing_continuous_prompts_for_generation.pdf
LoRA
| LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS | arXiv 2021 |
|---|
Abstract: We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
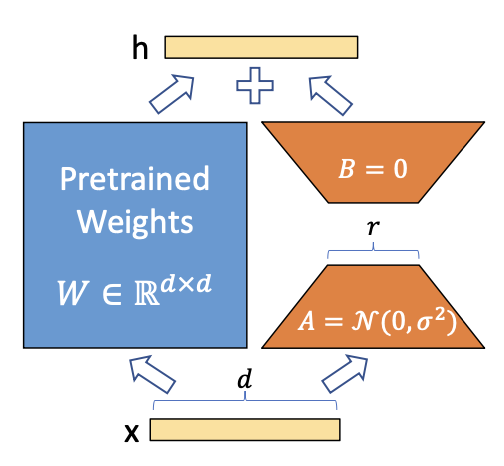
We limit our study to only adapting the attention weights for downstream tasks and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity and parameter-efficiency.
LST
| LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning | NeurIPS 2022 |
|---|
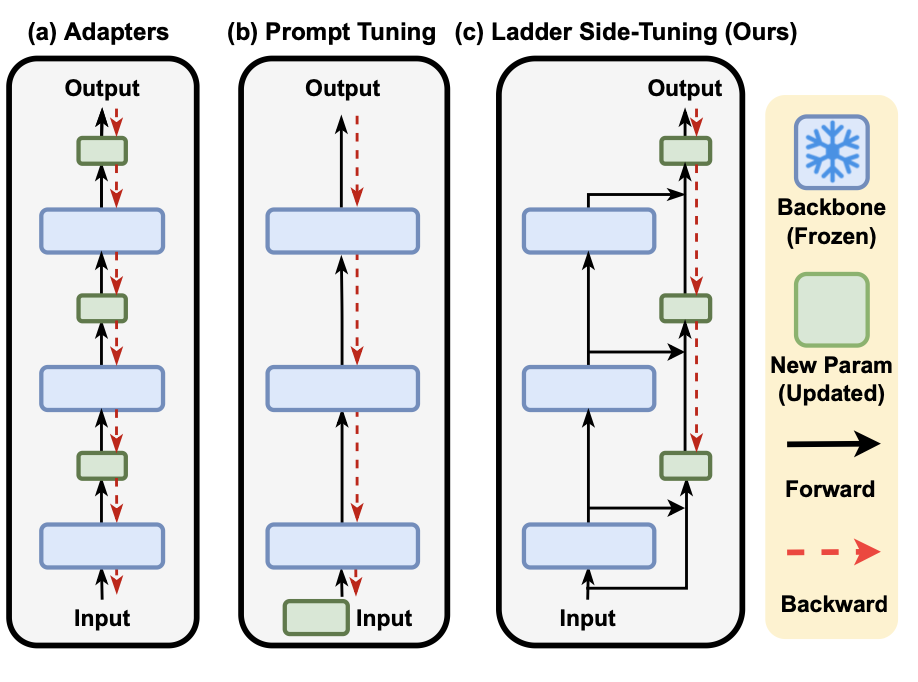
Transformer
Attention
Reading List:
flash-attention: Fast and memory-efficient exact attention. from github
Benchmark
glue_a_multi_task_benchmark_and_analysis_platform_for_natural_language_understand_ing.pdf