Privacy-Perserving Machine Learning
Paper
| TransLinkGuard: Safeguarding Transformer Models Against Model Stealing in Edge Deployment | arXiv 2024 |
|---|
Abstract: Proprietary large language models (LLMs) have been widely applied in various scenarios. Additionally, deploying LLMs on edge devices is trending for efficiency and privacy reasons. However, edge deployment of proprietary LLMs introduces new security challenges: edge-deployed models are exposed as white-box accessible to users, enabling adversaries to conduct effective model stealing (MS) attacks. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify four critical protection properties that existing methods fail to simultaneously satisfy: (1) maintaining protection after a model is physically copied; (2) authorizing model access at request level; (3) safeguarding runtime reverse engineering; (4) achieving high security with negligible runtime overhead. To address the above issues, we propose TransLinkGuard, a plug-and-play model protection approach against model stealing on edge devices. The core part of TransLinkGuard is a lightweight authorization module residing in a secure environment, e.g., TEE. The authorization module can freshly authorize each request based on its input. Extensive experiments show that TransLinkGuard achieves the same security protection as the black-box security guarantees with negligible overhead.
| A FAST, PERFORMANT, SECURE DISTRIBUTED TRAINING FRAMEWORK FOR LLM | ICASSP 2024 |
|---|
Abstract: The distributed (federated) LLM is an important method for co-training the domain-specific LLM using siloed data. How- ever, maliciously stealing model parameters and data from the server or client side has become an urgent problem to be solved. In this paper, we propose a secure distributed LLM based on model slicing. In this case, we deploy the Trusted Execution Environment (TEE) on both the client and server side, and put the fine-tuned structure (LoRA or embedding of P-tuning v2) into the TEE. Then, secure communication is executed in the TEE and general environments through lightweight encryption. In order to further reduce the equipment cost as well as increase the model performance and accuracy, we propose a split fine-tuning scheme. In particular, we split the LLM by layers and place the latter layers in a server-side TEE (the client does not need a TEE). We then combine the proposed Sparsification Parameter Fine-tuning (SPF) with the LoRA part to improve the accuracy of the downstream task. Numerous experiments have shown that our method guarantees accuracy while maintaining security. link
| ShadowNet: A Secure and Efficient On-device Model Inference System for Convolutional Neural Networks | SP 2023 |
|---|
Abstract: With the increased usage of AI accelerators on mobile and edge devices, on-device machine learning (ML) is gaining popularity. Thousands of proprietary ML models are being deployed today on billions of untrusted devices. This raises serious security concerns about model privacy. However, protecting model privacy without losing access to the untrusted AI accelerators is a challenging problem. In this paper, we present a novel on-device model inference system, ShadowNet. ShadowNet protects the model privacy with Trusted Execution Environment (TEE) while securely outsourcing the heavy linear layers of the model to the untrusted hardware accelerators. ShadowNet achieves this by transforming the weights of the linear layers before outsourcing them and restoring the results inside the TEE. The non-linear layers are also kept secure inside the TEE. ShadowNet’s design ensures efficient transformation of the weights and the subsequent restoration of the results. We build a ShadowNet prototype based on TensorFlow Lite and evaluate it on five popular CNNs, namely, MobileNet, ResNet44, MiniVGG, ResNet-404, and YOLOv4-tiny. Our evaluation shows that ShadowNet achieves strong security guarantees with reasonable performance, offering a practical solution for secure on-device model inference.
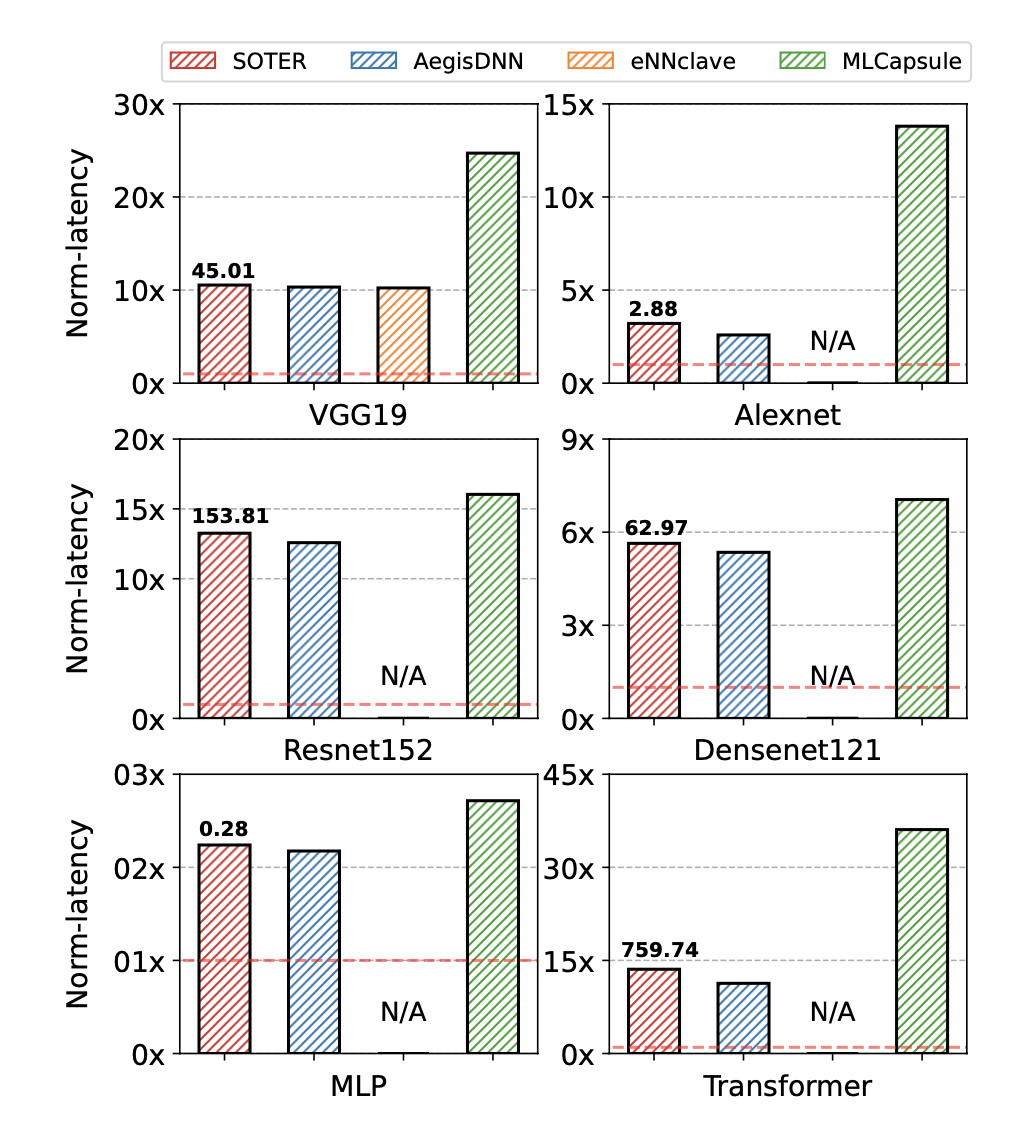
| Soter: Guarding Black-box Inference for General Neural Networks at the Edge | ATC 2022 |
|---|
Abstract: The prosperity of AI and edge computing has pushed more and more well-trained DNN models to be deployed on third- party edge devices to compose mission-critical applications. This necessitates protecting model confidentiality at untrusted devices, and using a co-located accelerator (e.g., GPU) to speed up model inference locally. Recently, the community has sought to improve the security with CPU trusted execu- tion environments (TEE). However, existing solutions either run an entire model in TEE, suffering from extremely high inference latency, or take a partition-based approach to hand- craft partial model via parameter obfuscation techniques to run on an untrusted GPU, achieving lower inference latency at the expense of both the integrity of partitioned computations outside TEE and accuracy of obfuscated parameters.
We propose SOTER, the first system that can achieve model confidentiality, integrity, low inference latency and high accuracy in the partition-based approach. Our key observation is that there is often an associativity property among many inference operators in DNN models. Therefore, SOTER automatically transforms a major fraction of associative operators into parameter-morphed, thus confidentiality-preserved op- erators to execute on untrusted GPU, and fully restores the execution results to accurate results with associativity in TEE. Based on these steps, SOTER further designs an oblivious fingerprinting technique to safely detect integrity breaches of morphed operators outside TEE to ensure correct executions of inferences. Experimental results on six prevalent models in the three most popular categories show that, even with stronger model protection, SOTER achieves comparable performance with partition-based baselines while retaining the same high accuracy as insecure inference. link
| Goten: GPU-Outsourcing Trusted Execution of Neural Network Training | AAAI 2020 |
|---|
Goten is based on the work of SLALOM
| SLALOM: FAST, VERIFIABLE AND PRIVATE EXECUTION OF NEURAL NETWORKS IN TRUSTED HARDWARE | ICLR 2019 |
|---|
Slalom, recently proposed by Tramer and Boneh, is the first solution that leverages both GPU (for efficient batch computation) and a trusted execution environment (TEE) (for minimizing the use of cryptography). link
| Delphi: A Cryptographic Inference Service for Neural Networks | Secur. Symp 2019 |
|---|
Delphi is based on Gazelle, using homomorphic encryption, grabled circuits, and secret shares to achieve client and server privacy protection in neural network inference. link
| Graviton: Trusted Execution Environments on GPUs | OSDI 2020 |
|---|
TransLinkGuard
| TransLinkGuard: Safeguarding Transformer Models Against Model Stealing in Edge Deployment | arXiv 2024 |
|---|
Abstract: Proprietary large language models (LLMs) have been widely applied in various scenarios. Additionally, deploying LLMs on edge devices is trending for efficiency and privacy reasons. However, edge deployment of proprietary LLMs introduces new security challenges: edge-deployed models are exposed as white-box accessible to users, enabling adversaries to conduct effective model stealing (MS) attacks. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify four critical protection properties that existing methods fail to simultaneously satisfy: (1) maintaining protection after a model is physically copied; (2) authorizing model access at request level; (3) safeguarding runtime reverse engineering; (4) achieving high security with negligible runtime overhead. To address the above issues, we propose TransLinkGuard, a plug-and-play model protection approach against model stealing on edge devices. The core part of TransLinkGuard is a lightweight authorization module residing in a secure environment, e.g., TEE. The authorization module can freshly authorize each request based on its input. Extensive experiments show that TransLinkGuard achieves the same security protection as the black-box security guarantees with negligible overhead.
SPF
| A FAST, PERFORMANT, SECURE DISTRIBUTED TRAINING FRAMEWORK FOR LLM | ICASSP 2024 |
|---|
Abstract: The distributed (federated) LLM is an important method for co-training the domain-specific LLM using siloed data. However, maliciously stealing model parameters and data from the server or client side has become an urgent problem to be solved. In this paper, we propose a secure distributed LLM based on model slicing. In this case, we deploy the Trusted Execution Environment (TEE) on both the client and server side, and put the fine-tuned structure (LoRA or embedding of P-tuning v2) into the TEE. Then, secure communication is executed in the TEE and general environments through lightweight encryption. In order to further reduce the equipment cost as well as increase the model performance and accuracy, we propose a split fine-tuning scheme. In particular, we split the LLM by layers and place the latter layers in a server-side TEE (the client does not need a TEE). We then combine the proposed Sparsification Parameter Fine-tuning (SPF) with the LoRA part to improve the accuracy of the downstream task. Numerous experiments have shown that our method guarantees accuracy while maintaining security
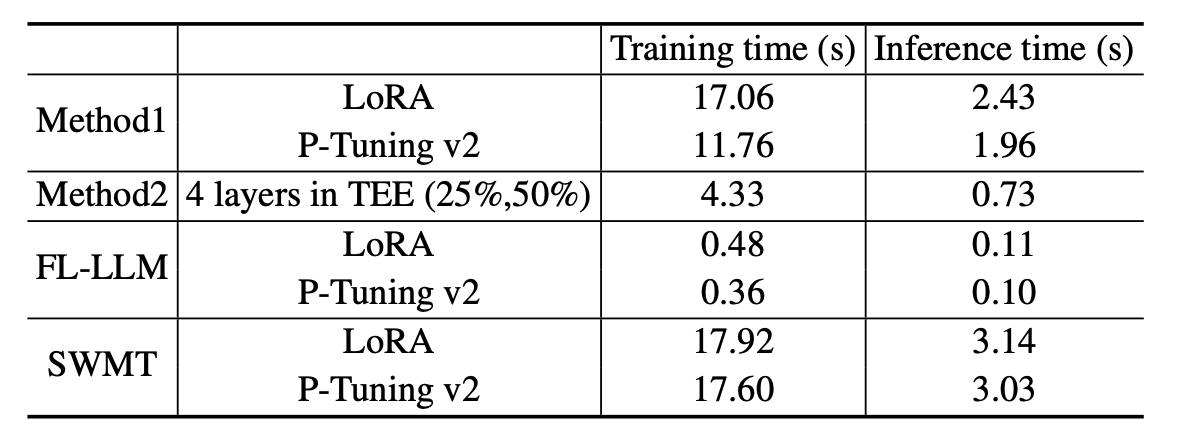
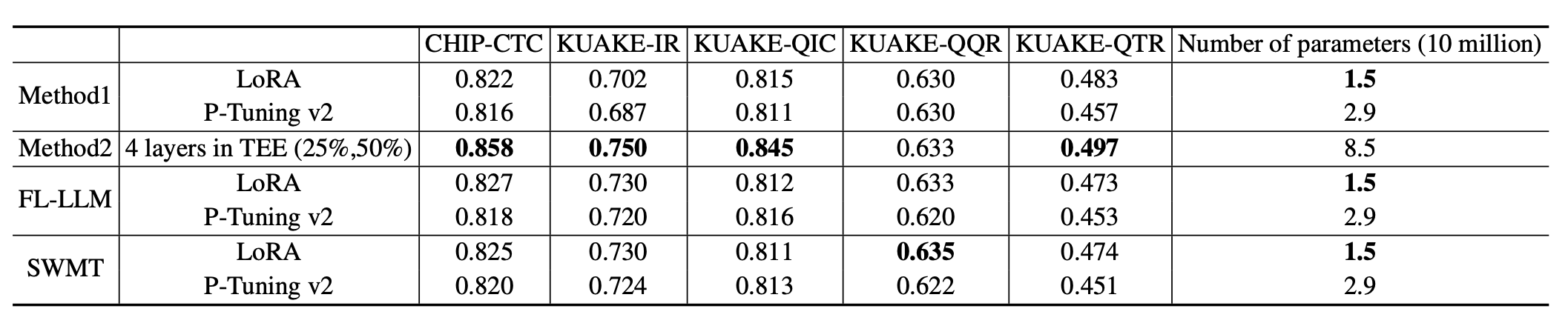
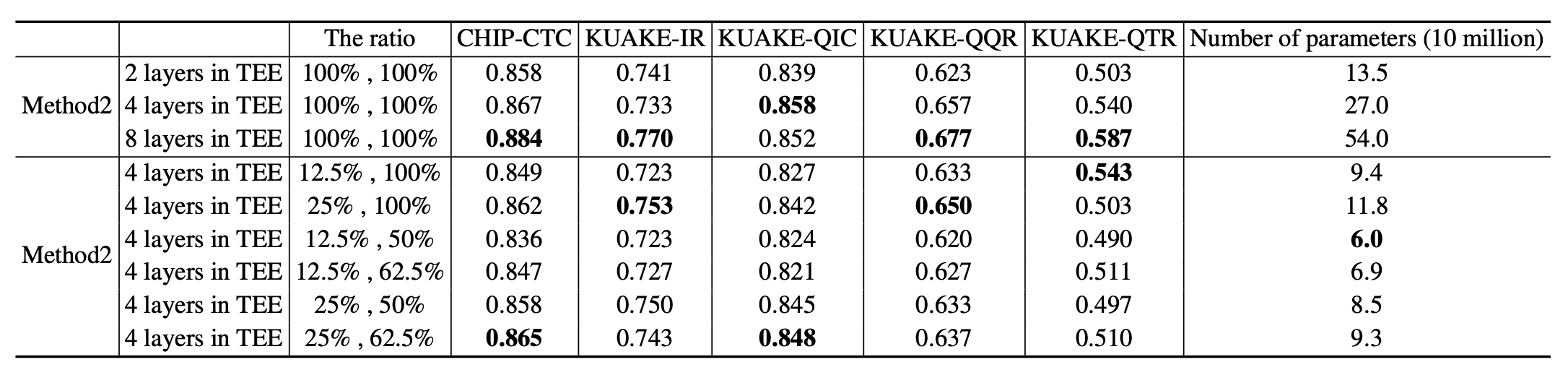
- Method 1: Using one-time pad encryption to protect the gradient of training in Federated Learning. The client needs to perform computation, and the server only needs to aggregate parameters.
- Method 2: Splitting the model into two parts: the first part of the model is fixed and computed by the client end, while the second part’s parameters are trained using fine-tuning on the server end.
- Using sparse fine-tuning and LoRA to reduce the number of parameters that need to be trained.
- Privacy Concern: The clients don’t interact with each other in Method 2, so there is no need to protect the computations of the clients.
- Result: 1) Method 1 is 33% faster than shielding whole-model by the TEE when using P-Tuning v2 fine-tuning, but shows almost same performance when using LoRA. 2) Method 2 is 75% faster than SWMT because the client doesn’t need to compute in TEE and the server uses sparse fine-tuning.
SOTER
SLALOM
| SLALOM: FAST, VERIFIABLE AND PRIVATE EXECUTION OF NEURAL NETWORKS IN TRUSTED HARDWARE | ICLR 2019 |
|---|
Slalom, recently proposed by Tramer and Boneh, is the first solution that leverages both GPU (for efficient batch computation) and a trusted execution environment (TEE) (for minimizing the use of cryptography).
Introduction
Challenge: A specific challenge they raised is that of appropriately splitting ML computations between trusted and untrusted components, to increase efficiency as well as security by minimizing the Trusted Computing Base.
Solution: This paper explores a novel approach to this challenge, wherein a Deep Neural Network (DNN) execution is partially outsourced from a TEE to a co-located, untrusted but faster device.
How to check integrity of outsource result?
Freivalds’ algorithm is a probabilistic randoized algorithm used to verify matrix multiplication.
Freivalds’ algorithm - Wikipedia
Freivalds' algorithm (named after Rūsiņš Mārtiņš Freivalds) is a probabilistic randomized algorithm used to verify matrix multiplication. Given three n × n matrices , , and , a general problem is to verify whether . A naïve algorithm would compute the product explicitly and compare term by term whether this product equals . However, the best known matrix multiplication algorithm runs in time.[1] Freivalds' algorithm utilizes randomization in order to reduce this time bound to [2] with high probability. In time the algorithm can verify a matrix product with probability of failure less than .









Safetynets is a framework that enables an untrusted server (the cloud) to provide a client with a short mathematical proof of the correctness of inference tasks that they perform on behalf of the client.
Solution
Privacy, $x$ is input, $r$ is random vector, $f$ is linear function. pre-computes $u=f(r)$, then TEE send $Enc(x)=x+r$ to unstrusted part, untrusted part then compute $f(Enc(x))$, TEE get result by $f(x)=f(x+r)-f(r)=f(Enc(x))-u$.
Discussion
-
Communication in Distributed System.
Slalom say,
In our setting, the TEE is co-located with the server’s faster untrusted processors, thus widening the design space to interactive outsourcing protocols with high communication but better efficiency.
so the overhead of communication in distributed system is not under consideration.
Slalom say,
Using Freivalds’ algorithm and symmetric encryption for each linear layer in a DNN incurs high interaction and communication between the TEE and untrusted co-processor (e.g., over 50MB per inference for VGG16, see Table 3). This would be prohibitive if they were not co-located.
ShadowNet
| ShadowNet: A Secure and Efficient On-device Model Inference System for Convolutional Neural Networks | SP 2023 |
|---|
Abstract: With the increased usage of AI accelerators on mobile and edge devices, on-device machine learning (ML) is gaining popularity. Thousands of proprietary ML models are being deployed today on billions of untrusted devices. This raises serious security concerns about model privacy. However, protecting model privacy without losing access to the untrusted AI accelerators is a challenging problem. In this paper, we present a novel on-device model inference system, ShadowNet. ShadowNet protects the model privacy with Trusted Execution Environment (TEE) while securely outsourcing the heavy linear layers of the model to the untrusted hardware accelerators. ShadowNet achieves this by transforming the weights of the linear layers before outsourcing them and restoring the results inside the TEE. The non-linear layers are also kept secure inside the TEE. ShadowNet’s design ensures efficient transformation of the weights and the subsequent restoration of the results. We build a ShadowNet prototype based on TensorFlow Lite and evaluate it on five popular CNNs, namely, MobileNet, ResNet44, MiniVGG, ResNet-404, and YOLOv4-tiny. Our evaluation shows that ShadowNet achieves strong security guarantees with reasonable performance, offering a practical solution for secure on-device model inference.
Delphi
Delphi: A Cryptographic Inference Service for Neural Networks
Gazelle using linearly-homomorphic encryption to compute linear layer, using grabled circuit to compute non-linear layer.
Delphi using preprocess and secret shares to imporve LHE performance, using using quadratic approximations to imporve the performance of grabled circuits, moreover, delphi design a planner to find appropriate non-linear layer to replace with quadratic approximations.
📌 Attacks
Indeed, such attacks have been successfully carried out even against systems that “perfectly” hide the model parameters by requiring the client to upload its input to the server [Fre+14; Ate+15; Fre+15; Wu+16b; Tra+16].
workflow: First, model provider optimize model via planner. Second, client and provider run the pre-processing phase for this model. Third, they run the online inference phase to get result of nerual network.
Solution
The linear layer involves the following steps: Given an input $ x \in \mathbb{R}^n $ (known only to the client), random vectors $ r_i \in \mathbb{R}^n $ and $ s_i \in \mathbb{R}^n $ are generated by the client and the server, respectively. The client sends $ \text{HE}(r_i) $, $ x_i - r_i $ to the server using homomorphic encryption. The model $ M $ is known only to the server. The server computes $ M_i r_i - s_i $ and $ M_i(x_i - r_i) + s_i $ using homomorphic encryption, then sends the results to the client. The client obtains $ M_i x_i $ through additive secret sharing.
Overview
| Field | Pros. | Cons. | Related Research |
|---|---|---|---|
| Confidential Computing | Easy to use, with low overhead costs. | 1) Only CPU-based trusted hardware is publicly available. 2) Communication between the trusted world and the normal world is costly. |
1) Outsource Computing (e.g. SLALOM/ShadowNet) 2) GPU-base trusted hardware architecture. (e.g. Graviton) 3) Criticality-aware smart encryption scheme 4) Outsource Computing based on fine tunning. |
| Federated Learning | Private data does not need to be shared with each other, only model weights should be shared. | 1) The model’s weight might leak private information. 2)the overhead of network communication. (It is not suitable for real-time task) |
|
| Homomorphic Encryption | 1) Slow. | ||
| Differential Privacy |
-
Federated Learning
Federated Machine Learning: Concept and Applications
Today’s AI still faces two major challenges. One is that in most industries, data exists in the form of isolated islands. The other is the strengthening of data privacy and security. We propose a possible solution to these challenges: secure federated learning. Beyond the federated learning framework first proposed by Google in 2016, we introduce a comprehensive secure federated learning framework, which includes horizontal federated learning, vertical federated learning and federated transfer learning. We provide definitions, architectures and applications for the federated learning framework, and provide a comprehensive survey of existing works on this subject. In addition, we propose building data networks among organizations based on federated mechanisms as an effective solution to allow knowledge to be shared without compromising user privacy.
-
Confidential Computing
Keep computing on memory private based on trusted hardware.
-
Homomorphic Encryption
-
Differential Privacy
Baseline
Baseline run NN fully in TEE.
- oblivious_multi_party_machine_learning_on_trusted_processors.pdf
- cvpr_2021_mlcapsule_guarded_offline_deployment_of_machine_learning_as_a_service.pdf
Trusted Execution Environment
Compare
| Paper | Problem | Challenge/Contribution |
|---|---|---|
| TransLinkGuard | ||
| SPF | malicious attacker(client/server) stealing data and parameter in the training of Federated LLM. | 1) Protect the data privacy in both the client and server sides of the Federated LLM system. 2) Balance between accuracy and performance when using fine-tuning. |
| ShadowNet | Protect the model of on-device machine learning. | 1)Protect the model privacy of on device. |
| Slalom | cloud based ML-as-a-Service platforms | 1) Protect the outsource computation using one-time-pad encryption. |
Homomorphic Encryption
gazelle_a_low_latency_framework_for_secure_neural_network_inference.pdf
Verifiable Execution
Safetynets is a framework that enables an untrusted server (the cloud) to provide a client with a short mathematical proof of the correctness of inference tasks that they perform on behalf of the client.
Quantization
Slide
Experiment
Related Paper
| Iron: Private Inference on Transformers | NeurIPS 2022 |
|---|
#HE
We initiate the study of private inference on Transformer-based models in the client-server setting, where clients have private inputs and servers hold proprietary models. Our main contribution is to provide several new secure protocols for matrix multiplication and complex non-linear functions like Softmax, GELU activations, and LayerNorm, which are critical components of Transformers. Specifically, we first propose a customized homomorphic encryption-based protocol for matrix multiplication that crucially relies on a novel compact packing technique. This design achieves √m× less communication (m is the number of rows of the output matrix) over the most efficient work. Second, we design efficient protocols for three non-linear functions via integrating advanced underlying protocols and specialized optimizations. Compared to the state-of-the-art protocols, our recipes reduce about half of the communication and computation overhead. Furthermore, all protocols are numerically precise, which preserve the model accuracy of plaintext. These techniques together allow us to implement Iron, an efficient Transformer-based private inference framework. Experiments conducted on several real-world datasets and models demonstrate that Iron achieves 3 ∼ 14× less communication and 3 ∼ 11× less runtime compared to the prior art.
| LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers | arXiv 2023 |
|---|
#HE #MPC
The community explored to build private inference frameworks for transformer- based large language models (LLMs) in a server-client setting, where the server holds the model parameters and the client inputs its private data (or prompt) for inference. However, these frameworks impose significant overhead when the private inputs are forward propagated through the original LLMs. In this paper, we show that substituting the computation and communication-heavy operators in the transformer architecture with privacy-computing friendly approximations can greatly reduce the private inference costs while incurring very minor impact on model performance. Compared to state-of-the-art Iron (NeurIPS 2022), our privacy-computing friendly model inference pipeline achieves a 5× acceleration in computation and an 80% reduction in communication overhead, while retaining nearly identical accuracy.
| SEALing Neural Network Models in Encrypted Deep Learning Accelerators | DAC 2021 |
|---|
Abstract—Deep learning (DL) accelerators suffer from a new security problem, i.e., being vulnerable to physical access based attacks. An adversary can easily obtain the entire neural network (NN) model by physically snooping the memory bus that connects the accelerator chip with DRAM memory. Therefore, memory encryption becomes important for DL accelerators to improve their security. Nevertheless, we observe that traditional memory encryption techniques that have been efficiently used in CPU systems cause significant performance degradation when directly used in DL accelerators, due to the big bandwidth gap between the memory bus and the encryption engine. To address this problem, our paper proposes SEAL, a Secure and Efficient Accelerator scheme for deep Learning to enhance the performance of encrypted DL accelerators by improving the data access band- width. Specifically, SEAL leverages a criticality-aware smart encryption scheme that identifies partial data having no impact on the security of NN models and allows them to bypass the encryption engine, thus reducing the amount of data to be encrypted without affecting security. Extensive experimental results demonstrate that, compared with existing memory encryption techniques, SEAL achieves 1.34−1.4× overall performance improvement.
| PRIVACY-PRESERVING IN-CONTEXT LEARNING FOR LARGE LANGUAGE MODELS | ICLR 2024 |
|---|
Abstract: In-context learning (ICL) is an important capability of Large Language Models (LLMs), enabling these models to dynamically adapt based on specific, in-context exemplars, thereby improving accuracy and relevance. However, LLM’s responses may leak the sensitive private information contained in in-context exemplars. To address this challenge, we propose Differentially Private In-context Learning (DP- ICL), a general paradigm for privatizing ICL tasks. The key idea for DP-ICL paradigm is generating differentially private responses through a noisy consensus among an ensemble of LLM’s responses based on disjoint exemplar sets. Based on the general paradigm of DP-ICL, we instantiate several techniques showing how to privatize ICL for text classification and language generation. We evaluate DP-ICL on four text classification benchmarks and two language generation tasks, and our empirical results show that DP-ICL achieves a strong utility-privacy tradeoff.
| Bicoptor: Two-round Secure Three-party Non-linear Computation without Preprocessing for Privacy-preserving Machine Learning | 2023 SP |
|---|
3-MPC Protocl for non-linear function overhead.
| A Berkeley View of Systems Challenges for AI |
|---|
| Oblivious Multi-Party Machine Learning on Trusted Processors | SS 2016 |
|---|